Machine Learning & Data Analysis of Online Chess Games
Overview
I analyzed over 40,000 online chess games to explore relationships between player ratings, outcomes, openings, and other variables. After conducting a detailed statistical and visual analysis using Python, Pandas, Matplotlib, and Seaborn, I designed a customized K-Nearest Neighbors (KNN) model to predict a player's rating based on their opening move, game outcome, and opponent skill level — achieving a median error rate within 1.5% of a player's true ranking.
In addition, I built a Generative Pretrained Transformer to play chess by continually predicting the next move within a sequence. I tested its performance against StockFish, the most powerful Chess Engine, in order to illustrate the potential, limitations, and modern approaches of applying attention-based AI architectures to domains currently dominated by traditional deep learning systems.
Data Analysis & Predictive Model Implementation
I collected two publicly available datasets: one of online Chess games, and another of famous games played by Grandmasters. In addition, I created a synthetic dataset of Chess games played by Stockfish, the most powerful Chess Engine. These were loaded into a Jupyter Notebook via the Pandas library.
With Matplotlib and Seaborn, I created visualizations to better understand the relationships between variables in the datasets and the between the datasets themselves. Here are a few notable examples:
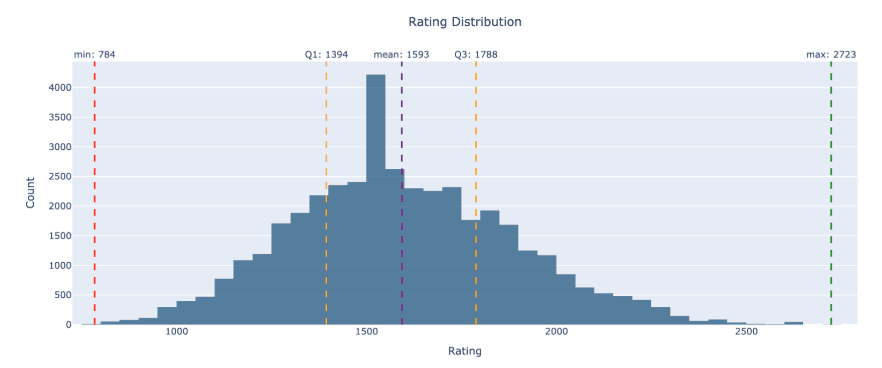
Player Rating Distribution:
Relationship between color, player ratings, and game outcomes:

Relationship between time control and number of moves:

Based on these findings, I designed a K-Nearest Neighbors (KNN) model to predict chess players' rankings using three key features: opponent skill level, game outcome, and opening move. The model employs a two-step filtering process to make its predictions:
- First, it narrows down the potential neighbors by only considering games that match both the opening move and game outcome of the target game.
- Then, from this filtered set, it selects the five most similar games based on opponent ranking similarity.
To illustrate: Consider predicting a player's ranking in a game where White won with an opening move of d4, facing an opponent rated 1500. The model would:
- Filter the dataset to only include games where White won with a d4 opening
- From these games, identify the five where the opponent's rating was closest to 1500
- Calculate a weighted average of these five players' ratings, (greater weight given to closer similarities)
To evaluate the model's performance, I split the data into training and testing sets. The model makes predictions for games in the testing set using only information from the training set. When compared against a baseline model (which predicted rankings based solely on opponent rating), the results were promising:

Based on these metrics, the KNN appears to make extremely precise predictions over half of the time. The main way it does this is through the relationship between the game outcome and the opponent's ranking: if White wins, beating an opponent that is ranked 1500, then they are likely to be ranked higher than 1500.
The first move played gives additional context: if the first move played is d4, that could directly indicate a slightly higher ranking for white, as d4 is, on average, preferred by higher-ranked players. More subtly, there could be relations between the variables that give the first move more predictive power: if white wins and their first move is d4, that could indicate a slightly different estimated ranking than games where white wins and their first move is e4.
Training a Generative Pretrained Transformer to play Chess
To build a transformer-based chess engine, I first created a custom tokenizer to encode chess moves. These moves are included in a consistent format (in chess notation) for each game, which allows us to configure a pytorch script to preprocess our data:
1# load the dataset & collect unique moves2data = pd.read_csv("chess_games.txt", header=None, names=["text"])3all_moves = set()4for game in data["text"]:5 moves = game.split() # Split each game by whitespace to derive moves6 all_moves.update(moves)78# add [UNK] to the vocabulary for unknown tokens9vocab = {move: idx for idx, move in enumerate(all_moves)}10vocab["[UNK]"] = len(vocab) # Add [UNK] token1112# initalize and save tokenizer13tokenizer = Tokenizer(WordLevel(vocab, unk_token="[UNK]"))14tokenizer.pre_tokenizer = Whitespace()15tokenizer.save("chess_tokenizer.json")
This allows us to interpret chess moves just as ChatGPT & other NLP algorithms interpret word tokens. In fact, with Word2Vec, we can visualize moves & games in 2D space:


With the tokenizer, we were able to train a GPT-2 model on the datasets of Chess games. This was done by loading a pre-trained HuggingFace GPT-2 model and training it with our chess data:
1# data processing2tokenizer = GPT2TokenizerFast(tokenizer_file="chess_tokenizer.json")3tokenizer.pad_token = tokenizer.eos_token # Set padding token4data = pd.read_csv("chess_games.txt", header=None, names=["text"])5dataset = Dataset.from_pandas(data)6dataset = dataset.train_test_split(test_size=0.1)78# GPT config9config = GPT2Config(10 vocab_size=tokenizer.vocab_size,11 n_positions=512,12 n_embd=512,13 n_layer=6,14 n_head=8,15)1617model = GPT2LMHeadModel(config)18model.resize_token_embeddings(len(tokenizer))1920# tokenize dataset function21def tokenize_function(examples):22 tokens = tokenizer(examples["text"], padding="max_length")23 tokens["labels"] = tokens["input_ids"].copy()24 return tokens2526tokenized_datasets = dataset.map(tokenize_function, remove_columns=27["text"])2829# training arguments:30training_args = TrainingArguments(31 output_dir="./results",32 evaluation_strategy="epoch",33 logging_strategy="steps",34 logging_steps=50,35 save_strategy="epoch",36 learning_rate=5e-4,37 weight_decay=0.01,38 per_device_train_batch_size=8,39 per_device_eval_batch_size=8,40 max_steps=5000,41 num_train_epochs=5,42 logging_dir='./logs',43 report_to="none",44)
After training, we now had a model that could predict the next move given in a sequence. I created a loop for our home-grown model to play against StockFish:
1# Initialize Stockfish2stockfish = Stockfish(3 path="/opt/homebrew/bin/stockfish",4 depth=18,5 parameters={6 "Threads": 2,7 "Minimum Thinking Time": 1000,8 "MultiPV": 39 }10)1112# Load GPT model13model_path = "fine_tuned_gpt2_chess"14model = GPT2LMHeadModel.from_pretrained(model_path)15tokenizer = GPT2TokenizerFast.from_pretrained(model_path)16model.eval()1718# Initialize the game19board = chess.Board()20move_history = []2122def get_gpt_move(current_position):23 formatted_moves = []24 for i, move in enumerate(move_history):25 if i % 2 == 0:26 formatted_moves.append(f"{(i//2)+1}. {move}")27 else:28 formatted_moves.append(move)2930 prompt = " ".join(formatted_moves)3132 print(f"Prompt sent to GPT: '{prompt}'")3334 input_ids = tokenizer(prompt, return_tensors="pt").input_ids3536 # generate next move37 output = model.generate(38 input_ids,39 max_length=input_ids.shape[1] + 2,40 do_sample=True,41 num_return_sequences=142 )43 generated_text = tokenizer.decode(output[0], skip_special_tokens=True)4445 print(f"Full GPT response: '{generated_text}'") # Debug print4647 # extract the last move from the generated sequence48 moves = generated_text.split()49 return moves[-1] if moves else None50
Our model was able to play coherently for most of the game—until getting into unknown positions, where it would try to play illegal moves. This is a common issue with transformer-based models, and is a topic of active research. In the future, training a more powerful model exclusively on strong players, and integrating Reinforcement Learning to encourage stronger moves, would likely improve performance massively. Traditional AI engines are likely to remain dominant in terms of raw strength; but, these GPT-based engines could be used to create more 'human-like' AI engines—by curating the dataset, we can create functioning chess engines that behave like specific players, styles, or eras.